Optimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation
简介
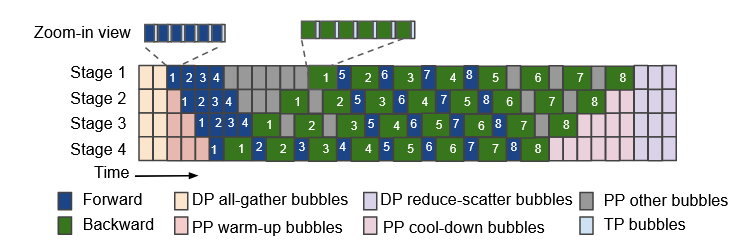
作者观察到在 3000 个 GPU 的集群训练多模态模型时,有 48% 的时间 GPU 都是空闲的,这些空闲时间有 90% 都是同步通信导致(下图),而 encoder 的计算相比 LLM 较少,之前的工作都没有将 encoder 和 LLM 同时考虑在一起优化,所以这篇文章的工作旨在想将多模态 encoder 的计算与 LLM 模块进行并行计算时通信重叠来提高并行效率(一句话概括文章主要想做的就是用 encoder 计算去和 LLM 并行计算中的通信重叠,达到同时利用通信和计算资源的目的来提高训练效率)。Optimus 在 Megatron-LM 的基础上实现,在 3072 个 GPU 的集群训练 ViT-22B 和 GPT-175B 模型时提升了 20.5% - 21.3% 的速度。
文章提出 Optimus 框架的动机主要来源于:
- 目前存在的训练框架,例如 Megatron-LM,MegaScale 等对多模块模型使用统一的并行策略(也即是说按照存在工作的并行策略大部分 GPU 都只包含 LLM 模块,无法将 encoder 的计算和 LLM 计算时的通信进行重叠);
- 数据依赖(例如在前向传播时,需要按照 encoder 到 LLM 的顺序,这样也没有重叠的机会,而实际在 PP 并行中拆分了 micro-batch 时进行一部分 encoder 计算就可以进行 LLM 部分的计算了, encoder 剩余部分将会有与 LLM 模块计算时通信重叠的机会);
- LLM 并行计算过程中的存在的通信时间长短不一(TP、PP 和 DP 通信时所需时间不同),已有的框架调度粒度大,导致重叠效率低(计算和通信没法完美重叠),文章指出将 encoder 层的计算分解为更小的 kernel 去重叠。
那么他需要解决的问题就有以下三点:
- 怎么切分模型,让 GPU 都包含 LLM 模型和 encoder 层。通过将 LLM 和 encoder 单独看待,然后使用不同的并行策略。
- 如何处理 PP 并行的数据依赖。核心就是 microbatch 级的调度。
- 如何尽可能重叠所有通信。将 encoder 的计算按照 kernel 级安排。
Optimus 的工作流如下图:先分模型,然后做 Bubble 调度(就是通信重叠)

ModelPlanner
这部分解法很直接(基于说 GPU 不太多,搜索空间不大,比如对于 LLM 模块 PP 并行度最多 64,TP 并行度最多 8),将 LLM 和 encoder 分开,暴力枚举并行策略,然后计算下内存开销裁剪下部分搜索空间。 dp + pp 时要 dp 需要的输入数据可以不均分,所以需要分配不同数量的 microbatch,分配方案也暴力枚举。
BubbleScheduler
如下图,先用 encoder 的计算粗填充由 DP 同步 LLM 模块梯度引起的空闲时间。
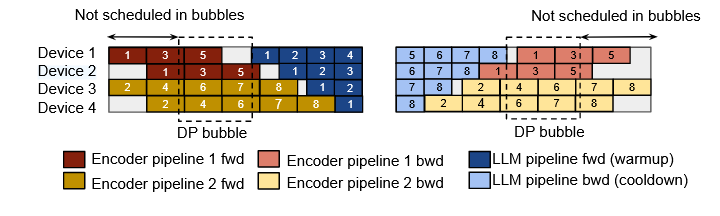
如何在将部分计算分解,检查下是否有依赖,没有就用分解后的 encoder 计算的 kernel 去填充其他的通信空闲,如下图(这一部分在文章没��写清楚细节,就是描述的思路,算法和文章还有图有点对不上,不知道是不是画错了)。例如在图中的第 8 个 microbatch 的计算可以延后一部分,把他的计算拿到后面的 llm 计算中去,保证在 llm 进行 microbatch 8 之前就行。
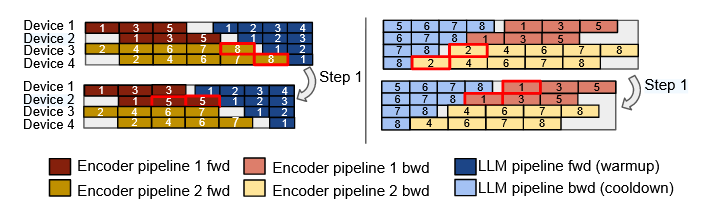
填充方式如下图,encoder 内部的计算也要满足计算依赖。
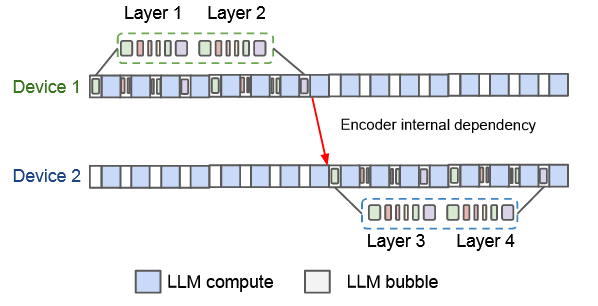
Address Encoder-LLM dependency
一个小的优化讨论,调整下流水线的排布,如下图,把 encoder 的计算延后去之后,再去安排调度就有更多的重叠机会(这里的讨论感觉和之前一样,我只要计算好哪些 microbatch 可以往后放直接分解为更小的 kernel 往后放就可以了,不知道为什么加这一章节没看明白)。

